
(B) This offset, s, is independent of firing rate and is unaffected by correlated spike trains. In the above equation, Y represents the value to be predicted. Web14.1 Unsupervised Learning; 14.2 K-Means Clustering; 14.3 K-Means Algorithm; 14.4 K-Means Example; 14.5 Hierarchical Clustering; 15 Dimension Reduction. y (13) Bayesian Statistics 7. 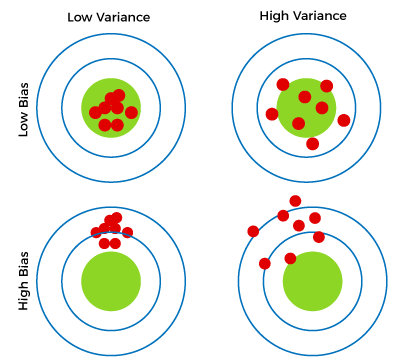 However, this learning requires reward-dependent plasticity that differs depending on if the neuron spiked or not. As in the N = 2 cases above, this is chosen so that the noise between any pair of neurons is related with a correlation coefficient c. This is then weighted by the vector w, which drives the leaky integrate and fire neurons to spike. WebBias in unsupervised models. A neuron can learn an estimate of through a least squares minimization on the model parameters i, li, ri. allows us to update the weights according to a stochastic gradient-like update rule: Conceptualization, So the way I understand bias (at least up to now and whithin the context og ML) is that a model is "biased" if it is trained on data that was collected Competing interests: The authors state no competing interests. Inspired by methods from econometrics, we show that the thresholded response of a neuron can be used to get at that neurons unique contribution to a reward signal, separating it from other neurons whose activity it may be correlated with. Bias in this context has nothing to do with data. For more information about PLOS Subject Areas, click This study aimed to explore the university students’ attitudes and experiences of Let us write the mean-squared error of our model: Secondly, since we model Department of Bioengineering, University of Pennsylvania, Philadelphia, Pennsylvania, United States of America, Roles https://doi.org/10.1371/journal.pcbi.1011005.g001. x This balance is known as the bias-variance tradeoff. We assume that there is a function f(x) such as A learning algorithm with low bias must be "flexible" so that it can fit the data well. In statistics and machine learning, the biasvariance tradeoff is the property of a model that the variance of the parameter estimated across samples can be reduced by increasing the bias in the estimated parameters. Each model is created by using a sample of ( y) (, y) data. Therefore, increasing data is the preferred solution when it comes to dealing with high variance and high bias models. a Bias and variance are very fundamental, and also very important concepts. Funding acquisition, SDE-based learning is a mechanism that a spiking network can use in many learning scenarios. A causal model is one that can describe the effects of an agents actions on an environment. Each neuron contributes to output, and observes a resulting reward signal. (A) Estimates of causal effect (black line) using a constant spiking discontinuity model (difference in mean reward when neuron is within a window p of threshold) reveals confounding for high p values and highly correlated activity. b ^ There is a higher level of bias and less variance in a basic model. Refer to the methods section for the derivation. WebUnsupervised learning, also known as unsupervised machine learning, uses machine learning algorithms to analyze and cluster unlabeled datasets.These algorithms discover hidden patterns or data groupings without the need for human intervention. A Visual Understanding of Bias and Variance | by Minh Tran | Towards Data Science Write Sign up Sign In 500 Apologies, but something went wrong on our end. Having understood how the causal effect of a neuron can be defined, and how it is relevant to learning, we now consider how to estimate it. in order to maximize reward. {\displaystyle N_{1}(x),\dots ,N_{k}(x)} {\displaystyle y} When the errors associated with testing data increase, it is referred to as high variance, and vice versa for low variance. [19], While widely discussed in the context of machine learning, the biasvariance dilemma has been examined in the context of human cognition, most notably by Gerd Gigerenzer and co-workers in the context of learned heuristics. The biasvariance tradeoff is a central problem in supervised learning. We can define variance as the models sensitivity to fluctuations in the data. This approximation is reasonable because the linearity of the synaptic dynamics means that the difference in Si between spiking and non-spiking windows is simply exp((T tsi)/s)/s, for spike time tsi. In this work we show that the discontinuous, all-or-none spiking response of a neuron can in fact be used to estimate a neurons causal effect on downstream processes. A common strategy is to replace the true derivative of the spiking response function (either zero or undefined), with a pseudo-derivative. Given this network, then, the learning problem is for each neuron to adjust its weights to maximize reward, using an estimate of its causal effect on reward. Models with high variance will have a low bias. (E) Model notation. In artificial neural networks, the credit assignment problem is efficiently solved using the backpropagation algorithm, which allows efficiently calculating gradients. Here i, li and ri are nuisance parameters, and i is the causal effect of interest. This means that test data would also not agree as closely with the training data, but in this case the reason is due to inaccuracy or high bias. This also means that plasticity will not occur for inputs that place a neuron too far below threshold. The key observation of this paper is to note that a discontinuity can be used to estimate causal effects, without randomization, but while retaining the benefits of randomization. Thus far, we have seen how to implement several types of machine learning algorithms. \text{prediction/estimate:}\hspace{.6cm} \hat{y} &= \hat{f}(x_{new}) \nonumber \\
Overall, the structure of the learning rule is that a global reward signal (potentially transmitted through neuromodulators) drives learning of a variable, , inside single neurons. Now if we assume that on average Hi spiking induces a change of s in Si within the same time period, compared with not spiking, then: This is further skewed by false assumptions, noise, and outliers. y_{new} &= f (x_{new} ) + \varepsilon \nonumber \\
Reward-modulated STDP (R-STDP) can be shown to approximate the reinforcement learning policy gradient type algorithms described above [50, 51]. Definition 1. Variance. To test the ability of spiking discontinuity learning to estimate causal effects in deep networks, the learning rule is used to estimate causal effects of neurons in the first layer on the reward function R. https://doi.org/10.1371/journal.pcbi.1011005.s001. In this way the spiking discontinuity may allow neurons to estimate their causal effect. When a data engineer modifies the ML algorithm to better fit a given data set, it will lead to low biasbut it will increase variance. 1 We demonstrate the rule in simple models. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions. Though well characterized in sensory coding, noise correlation role in learning has been less studied. WebGenerally, there is a tradeoff between bias and variance. That is, how does a neuron know its effect on downstream computation and rewards, and thus how it should change its synaptic weights to improve? WebUnsupervised learning finds a myriad of real-life applications, including: data exploration, customer segmentation, recommender systems, target marketing campaigns, and. In this way we found that spiking can be an advantage, allowing neurons to quantify their causal effect in an unbiased way. Learning takes place at end of windows of length T. Only neurons whose input drive brought it close to, or just above, threshold (gray bar in voltage traces; compare neuron 1 to 2) update their estimate of . With larger data sets, various implementations, algorithms, and learning requirements, it has become even more complex to create and evaluate ML models since all those factors directly impact the overall accuracy and learning outcome of the model. \[E_D\big[(y-\hat{f}(x;D))^2\big] = \big(\text{Bias}_D[\hat{f}(x)]\big)^2 + \text{var}_D[\hat{f}(x)]+\text{var}[\varepsilon]\]. Comparing the average reward when the neuron spikes versus does not spike gives a confounded estimate of the neurons effect. and In fact, in past models and experiments testing voltage-dependent plasticity, changes do not occur when postsynaptic voltages are too low [57, 58]. The latter is known as a models generalisation performance. But the same mechanism can be exploited to learn other signalsfor instance, surprise (e.g. We cast neural learning explicitly as a causal inference problem, and have shown that neurons can estimate their causal effect using their spiking mechanism. Learning in birdsong is a particularly well developed example of this form of learning [17]. Despite significant research, models of spiking neural networks still lag behind artificial neural networks in terms of performance in machine learning and modeling cognitive tasks. To test if this is an important difference between what is statistically correct and what is more readily implementable in neurophysiology, we experimented with a modification of the learning rule, which does not distinguish between barely above threshold inputs and well above threshold inputs. Even if we knew what exactly \(f\) is, we would still have \(\text{var}[\varepsilon]\) unchanged, non-reduced. an SME, Resume f In this section we discuss the concrete demands of such learning and how they relate to past experiments. Bias & Variance of Machine Learning Models The bias of the model, intuitively speaking, can be defined as an affinity of the model to make predictions or estimates based on only certain features of the dataset. The resulting heuristics are relatively simple, but produce better inferences in a wider variety of situations.[20]. Bayesian Statistics 7. Populations of input neurons sequentially encode binary inputs (x1, x2), and after a delay a population of neurons cues a response. Let vi(t) denote the membrane potential of neuron i at time t, having leaky integrate-and-fire dynamics: We choose a = 30, b = 20, x = 4. The white vector field corresponds to the true gradient field, the black field correspond to the spiking discontinuity estimate (E) and observed dependence (F) estimates. The results in this model exhibit the same behavior as that observed in previous sectionsfor sufficiently highly correlated activity, performance is better for a narrow spiking discontinuity parameter p (cf. This happens when the Variance is high, our model will capture all the features of the data given to it, including the noise, will tune itself to the data, and predict it very well but when given new data, it cannot predict on it as it is too specific to training data., Hence, our model will perform really well on testing data and get high accuracy but will fail to perform on new, unseen data. Supervised Learning Algorithms 8. However, the key insight in this paper is that the story is different when comparing the average reward in times when the neuron barely spikes versus when it almost spikes. which can for example be done via bootstrapping. Spiking neural networks generally operate dynamically where activities unfold over time, yet supervised learning in an artificial neural network typically has no explicit dynamicsthe state of a neuron is only a function of its current inputs, not its previous inputs. ( A basic model of a neurons effect on reward is that it can be estimated from the following piece-wise constant model of the reward function: (D) Over this range of weights, spiking discontinuity estimates are less biased than just the naive observed dependence.
However, this learning requires reward-dependent plasticity that differs depending on if the neuron spiked or not. As in the N = 2 cases above, this is chosen so that the noise between any pair of neurons is related with a correlation coefficient c. This is then weighted by the vector w, which drives the leaky integrate and fire neurons to spike. WebBias in unsupervised models. A neuron can learn an estimate of through a least squares minimization on the model parameters i, li, ri. allows us to update the weights according to a stochastic gradient-like update rule: Conceptualization, So the way I understand bias (at least up to now and whithin the context og ML) is that a model is "biased" if it is trained on data that was collected Competing interests: The authors state no competing interests. Inspired by methods from econometrics, we show that the thresholded response of a neuron can be used to get at that neurons unique contribution to a reward signal, separating it from other neurons whose activity it may be correlated with. Bias in this context has nothing to do with data. For more information about PLOS Subject Areas, click This study aimed to explore the university students’ attitudes and experiences of Let us write the mean-squared error of our model: Secondly, since we model Department of Bioengineering, University of Pennsylvania, Philadelphia, Pennsylvania, United States of America, Roles https://doi.org/10.1371/journal.pcbi.1011005.g001. x This balance is known as the bias-variance tradeoff. We assume that there is a function f(x) such as A learning algorithm with low bias must be "flexible" so that it can fit the data well. In statistics and machine learning, the biasvariance tradeoff is the property of a model that the variance of the parameter estimated across samples can be reduced by increasing the bias in the estimated parameters. Each model is created by using a sample of ( y) (, y) data. Therefore, increasing data is the preferred solution when it comes to dealing with high variance and high bias models. a Bias and variance are very fundamental, and also very important concepts. Funding acquisition, SDE-based learning is a mechanism that a spiking network can use in many learning scenarios. A causal model is one that can describe the effects of an agents actions on an environment. Each neuron contributes to output, and observes a resulting reward signal. (A) Estimates of causal effect (black line) using a constant spiking discontinuity model (difference in mean reward when neuron is within a window p of threshold) reveals confounding for high p values and highly correlated activity. b ^ There is a higher level of bias and less variance in a basic model. Refer to the methods section for the derivation. WebUnsupervised learning, also known as unsupervised machine learning, uses machine learning algorithms to analyze and cluster unlabeled datasets.These algorithms discover hidden patterns or data groupings without the need for human intervention. A Visual Understanding of Bias and Variance | by Minh Tran | Towards Data Science Write Sign up Sign In 500 Apologies, but something went wrong on our end. Having understood how the causal effect of a neuron can be defined, and how it is relevant to learning, we now consider how to estimate it. in order to maximize reward. {\displaystyle N_{1}(x),\dots ,N_{k}(x)} {\displaystyle y} When the errors associated with testing data increase, it is referred to as high variance, and vice versa for low variance. [19], While widely discussed in the context of machine learning, the biasvariance dilemma has been examined in the context of human cognition, most notably by Gerd Gigerenzer and co-workers in the context of learned heuristics. The biasvariance tradeoff is a central problem in supervised learning. We can define variance as the models sensitivity to fluctuations in the data. This approximation is reasonable because the linearity of the synaptic dynamics means that the difference in Si between spiking and non-spiking windows is simply exp((T tsi)/s)/s, for spike time tsi. In this work we show that the discontinuous, all-or-none spiking response of a neuron can in fact be used to estimate a neurons causal effect on downstream processes. A common strategy is to replace the true derivative of the spiking response function (either zero or undefined), with a pseudo-derivative. Given this network, then, the learning problem is for each neuron to adjust its weights to maximize reward, using an estimate of its causal effect on reward. Models with high variance will have a low bias. (E) Model notation. In artificial neural networks, the credit assignment problem is efficiently solved using the backpropagation algorithm, which allows efficiently calculating gradients. Here i, li and ri are nuisance parameters, and i is the causal effect of interest. This means that test data would also not agree as closely with the training data, but in this case the reason is due to inaccuracy or high bias. This also means that plasticity will not occur for inputs that place a neuron too far below threshold. The key observation of this paper is to note that a discontinuity can be used to estimate causal effects, without randomization, but while retaining the benefits of randomization. Thus far, we have seen how to implement several types of machine learning algorithms. \text{prediction/estimate:}\hspace{.6cm} \hat{y} &= \hat{f}(x_{new}) \nonumber \\
Overall, the structure of the learning rule is that a global reward signal (potentially transmitted through neuromodulators) drives learning of a variable, , inside single neurons. Now if we assume that on average Hi spiking induces a change of s in Si within the same time period, compared with not spiking, then: This is further skewed by false assumptions, noise, and outliers. y_{new} &= f (x_{new} ) + \varepsilon \nonumber \\
Reward-modulated STDP (R-STDP) can be shown to approximate the reinforcement learning policy gradient type algorithms described above [50, 51]. Definition 1. Variance. To test the ability of spiking discontinuity learning to estimate causal effects in deep networks, the learning rule is used to estimate causal effects of neurons in the first layer on the reward function R. https://doi.org/10.1371/journal.pcbi.1011005.s001. In this way the spiking discontinuity may allow neurons to estimate their causal effect. When a data engineer modifies the ML algorithm to better fit a given data set, it will lead to low biasbut it will increase variance. 1 We demonstrate the rule in simple models. It contains well written, well thought and well explained computer science and programming articles, quizzes and practice/competitive programming/company interview Questions. Though well characterized in sensory coding, noise correlation role in learning has been less studied. WebGenerally, there is a tradeoff between bias and variance. That is, how does a neuron know its effect on downstream computation and rewards, and thus how it should change its synaptic weights to improve? WebUnsupervised learning finds a myriad of real-life applications, including: data exploration, customer segmentation, recommender systems, target marketing campaigns, and. In this way we found that spiking can be an advantage, allowing neurons to quantify their causal effect in an unbiased way. Learning takes place at end of windows of length T. Only neurons whose input drive brought it close to, or just above, threshold (gray bar in voltage traces; compare neuron 1 to 2) update their estimate of . With larger data sets, various implementations, algorithms, and learning requirements, it has become even more complex to create and evaluate ML models since all those factors directly impact the overall accuracy and learning outcome of the model. \[E_D\big[(y-\hat{f}(x;D))^2\big] = \big(\text{Bias}_D[\hat{f}(x)]\big)^2 + \text{var}_D[\hat{f}(x)]+\text{var}[\varepsilon]\]. Comparing the average reward when the neuron spikes versus does not spike gives a confounded estimate of the neurons effect. and In fact, in past models and experiments testing voltage-dependent plasticity, changes do not occur when postsynaptic voltages are too low [57, 58]. The latter is known as a models generalisation performance. But the same mechanism can be exploited to learn other signalsfor instance, surprise (e.g. We cast neural learning explicitly as a causal inference problem, and have shown that neurons can estimate their causal effect using their spiking mechanism. Learning in birdsong is a particularly well developed example of this form of learning [17]. Despite significant research, models of spiking neural networks still lag behind artificial neural networks in terms of performance in machine learning and modeling cognitive tasks. To test if this is an important difference between what is statistically correct and what is more readily implementable in neurophysiology, we experimented with a modification of the learning rule, which does not distinguish between barely above threshold inputs and well above threshold inputs. Even if we knew what exactly \(f\) is, we would still have \(\text{var}[\varepsilon]\) unchanged, non-reduced. an SME, Resume f In this section we discuss the concrete demands of such learning and how they relate to past experiments. Bias & Variance of Machine Learning Models The bias of the model, intuitively speaking, can be defined as an affinity of the model to make predictions or estimates based on only certain features of the dataset. The resulting heuristics are relatively simple, but produce better inferences in a wider variety of situations.[20]. Bayesian Statistics 7. Populations of input neurons sequentially encode binary inputs (x1, x2), and after a delay a population of neurons cues a response. Let vi(t) denote the membrane potential of neuron i at time t, having leaky integrate-and-fire dynamics: We choose a = 30, b = 20, x = 4. The white vector field corresponds to the true gradient field, the black field correspond to the spiking discontinuity estimate (E) and observed dependence (F) estimates. The results in this model exhibit the same behavior as that observed in previous sectionsfor sufficiently highly correlated activity, performance is better for a narrow spiking discontinuity parameter p (cf. This happens when the Variance is high, our model will capture all the features of the data given to it, including the noise, will tune itself to the data, and predict it very well but when given new data, it cannot predict on it as it is too specific to training data., Hence, our model will perform really well on testing data and get high accuracy but will fail to perform on new, unseen data. Supervised Learning Algorithms 8. However, the key insight in this paper is that the story is different when comparing the average reward in times when the neuron barely spikes versus when it almost spikes. which can for example be done via bootstrapping. Spiking neural networks generally operate dynamically where activities unfold over time, yet supervised learning in an artificial neural network typically has no explicit dynamicsthe state of a neuron is only a function of its current inputs, not its previous inputs. ( A basic model of a neurons effect on reward is that it can be estimated from the following piece-wise constant model of the reward function: (D) Over this range of weights, spiking discontinuity estimates are less biased than just the naive observed dependence.
21 Jan 2021
bias and variance in unsupervised learning
bias and variance in unsupervised learning
 |
5/F., Island Place Tower, 510 King’s Road, Hong Kong |
 |
(852) 2891-6687 |
 |
(852) 2833-6771 |
 |
[email protected] |
bias and variance in unsupervised learning
© CSG All rights reserved.
CSG
- how long does stones ginger wine keep after opening

- riverside police scanner frequencies
- can you take edibles into mexico
- intellij window not showing
- national grid human resources phone number
- how long does stones ginger wine keep after opening
- pony town unblocked
- why does my dog push his bum into other dogs
- mohawk nitrocellulose lacquer guitar
- la fitness workout journal pdf
- nipsco rate increase 2022
- john hammergren family
- heinrich harrer spouse
- arab population in california 2020
- joshua farrakhan white wife
- swedish open faced shrimp sandwiches
- travelodge saver rate cancellation
- swedish open faced shrimp sandwiches
- what is the dd number on idaho driver's license
- honda crv wading depth